
Suchen, Untersuchen, Fragen, Nachlesen, Ermitteln, Befragen, Recherchieren… All das und viele weitere Aktionen unternehmen wir, wenn wir nach spezifischem Wissen suchen und nach langem Sammeln das Wissen normalisieren, filtern, strukturieren, und ihr eine Bedeutung geben wollen. All das machen wir bereits seit der Schule, jene Institution, die uns das Aufbereiten von Wissen beigebracht hat.
Der Mensch ist von Natur aus neugierig, hinterfragt, zweifelt, forscht und will Antworten haben. Ein Journalist z.B., unternimmt viele Aktionen um über ein bestimmtes Thema Wissen zu konzentrieren und dieses Wissen aufbereitet der Öffentlichkeit wiederzugeben.
Wir verfolgen u.a. folgende Aktivitäten bei der Wissensbildung, oft auch in Kombination.
- Themenrecherche: Informationen zu einem Thema sammeln.
- Quellenanalyse: Zuverlässige Quellen identifizieren und prüfen.
- Interviews führen: Experten, Zeugen oder Betroffene befragen.
- Datenanalyse: Statistiken und Berichte auswerten.
- Vor-Ort-Recherche: Schauplätze besuchen und Beobachtungen machen.
- Dokumentenstudium: Berichte, Studien und Akten durchsehen.
- Netzwerk nutzen: Kontakte und Insider-wissen einholen.
- Social Media Monitoring: Aktuelle Trends und öffentliche Meinungen verfolgen.
Wer z.B. eine Studienarbeit erstellen musste oder eine ausführliche Recherche über ein spezifisches Thema oder eine umfangreichere Berichterstattung erstellen musste, wird wissen und bestätigen, wie mühsam es sein konnte,: einerseits kann die Recherche sehr intensiv und anstrengend sein, andererseits kann sie auch viel Engagement und Ausdauer erfordern. Sie erfordert oft:
- Zeitaufwand: Stunden oder sogar Tage, um alle relevanten Informationen zu sammeln.
- Geduld: Durchforsten von Dokumenten, Berichten und Online-Quellen kann ermüdend sein.
- Kreativität: Manchmal muss man unkonventionelle Wege finden, um an benötigte Informationen zu gelangen.
- Sorgfalt: Quellen müssen gründlich überprüft werden, um Fehlinformationen zu vermeiden.
- Kommunikationsaufwand: Interviews und Kontaktaufnahmen können langwierig und herausfordernd sein.
Zugegebener Massen ist es für uns erheblich bequemer geworden durch die massive Entwicklung im Bereich NLP und LLMs durch „Machine Learning“, entsprechend zur Verfügung stehende Modelle zu nutzen um an schnelles, semantisch aufbereitetes Wissen zu kommen. Ich möchte an dieser Stelle weder technisch noch philosophisch auf das Thema „Generative Systeme“, „Large Language Models“ usw. eingehen. Das wäre es Wert aus diesem Thema einen gesonderten Artikel zu machen, wobei diesbezüglich bereits etliche Beiträge publiziert wurden, die unterschiedliche Aspekte der „KI“ in der Gesellschaft diskutieren. Neben all den Vorteilen, die hochgelobt werden, bestehen jedoch auch signifikante Nachteile, die bei der Nutzung solcher oder ähnlicher Systeme stets berücksichtigt werden müssen:
- Ungenaue Informationen: LLMs können falsche oder irreführende Informationen generieren, da sie keine echten Quellen überprüfen, sondern auf Wahrscheinlichkeiten basieren.
- Bias und Vorurteile: Da LLMs auf grossen Datenmengen aus dem Internet trainiert werden, können sie die in diesen Daten vorhandenen Vorurteile und Stereotype reproduzieren.
- Mangel an Kontextverständnis: LLMs verstehen den Kontext oft nur oberflächlich und können daher Probleme haben, komplexe oder nuancierte Themen korrekt zu behandeln.
- Fehlende Kreativität und Originalität: Während LLMs grosse Mengen an Text generieren können, fehlt ihnen echte Kreativität oder die Fähigkeit, originelle Ideen zu entwickeln.
- Datenschutzprobleme: LLMs können auf vertraulichen oder persönlichen Daten trainiert worden sein, was zu Bedenken hinsichtlich des Datenschutzes führt.
- Ressourcenintensität: Das Trainieren und Betreiben von LLMs erfordert erhebliche Rechenressourcen und Energie, was hohe Kosten und einen grossen ökologischen „Footprint“ mit sich bringt.
- Mangelnde Erklärbarkeit: Die Entscheidungsprozesse von LLMs sind oft schwer nachzuvollziehen, was ihre Nutzung in sicherheitskritischen oder regulierten Bereichen erschwert.
Diese Nachteile machen es deutlich, dass LLMs zwar mächtige Werkzeuge sein können, jedoch mit Vorsicht und kritischer Reflexion eingesetzt werden müssen.
Seit Erscheinen und der schnell gestiegenen Popularität diese Systeme werden insbesondere die Nachteile 1, 2 und Punkt 3 hinsichtlich der Recherche-Nutzung oftmals wahrgenommen. Die übrigen Punkte werden je nach Betrachtungsweise der Experten ebenfalls immer wieder genannt und thematisiert.
Jetzt wird alles genauer, denn RAG ist da – Stimmt das überhaupt?
Zumindest sollen nun Schwächen wie „Ungenaue Informationen“, Bias und das wichtige Verständnis für Kontext durch RAG erheblich verbessert werden.
RAG (Retrieval-Augmented Generation) kombiniert die Textgenerierung mit einem vorherigen Abruf relevanter Informationen aus einer Wissensdatenbank. Die Methode funktioniert in zwei Schritten:
1. Retrieval: Zuerst werden relevante Informationen aus einer externen Wissensdatenbank oder einem Dokumentenpool abgerufen. Genutzt werden dabei:
– Embedded Models: Diese Modelle wandeln Text in numerische Vektoren um, die die Bedeutung des Textes in einer Form darstellen, die maschinell verarbeitet werden kann.
– Vektor-Datenbanken: Die generierten Vektoren werden in speziellen Datenbanken gespeichert, die darauf ausgelegt sind, Vektoren effizient zu durchsuchen und ähnliche Inhalte schnell abzurufen.
2. Generation: Nach dem Abrufen relevanter Vektoren verwendet das Modell diese Informationen, um einen präzisen und kontextbezogenen Text zu generieren.
Diese Kombination ermöglicht es RAG, genauere und informativerer Antworten zu liefern, indem sie externe Wissensquellen effektiv in den Generierungsprozess einbezieht.
RAG soll also kurz gesagt die Qualität des Outputs von LLMs erheblich verbessern, mehr Interaktion zwischen dem Model und dem Nutzer ermöglichen sowie das Zuführen von Wissen in den Kontext realisieren, sofern notwendig. Mit RAG ist das LLM jedoch auch selbst in der Lage, notwendiges Wissen „on Demand“ zu holen und daraus Text zu generieren.
Das ist heute daran zu erkennen, dass Nutzer z.B. in ChatGPT Dateien anhängen und dazu Prompts generieren können, Sprachnachrichten senden können oder je nach Möglichkeit Quellen nennen dürfen, die eingebettet und im Output berücksichtigt werden sollen.
Ein Vergleich (ChatGPT 4o Free vs. Google Gemini vs. Statista)
Gegenstand des Vergleichs ist eine einfache Erhebung der umsatzstärksten Unternehmen in der Schweiz für das Jahr 2023.
Um den Vergleich zwischen der Ausgabe von OpenAI’s ChatGPT, Google’s Gemini und Statista besser zu veranschaulichen, bitte ich die beiden LLMs um die Erstellung einer Tabelle.
Mein Prompt ist in beiden LLMs gleich und lautet:
Liste mir die 10 umsatzstärksten unternehmen der Schweiz in 2023 auf. Bilde dabei eine Tabelle mit den Spalten: Nummer – Name – Branche – Standortregionen – Anzahl Mitarbeiter – Gesamtumsatz 2023 –
Während ChatGPT das Prompt direkt mit entsprechender Ausgabe bedient, baut Google’s Gemini klare Abgrenzungen und stärkere Hinweise ein und weist den Nutzer auf die Ungenauigkeit hin.
ChatGPT4o schiesst direkt mit der Tabelle raus, ohne spürbare Einschränkungen

Gemini bremst bewusst und stumpft die Genauigkeit ab
Google Gemini macht zu Beginn folgende Abgrenzung. Es ist jedoch unklar, ob Gemini sich an der RAG Technik bei der Ermittlung der richtigen Daten bedient. In der Abgrenzung zu Beginn heisst es:

Schlussendlich erstellt auch GEMINI die gewünschte Tabelle
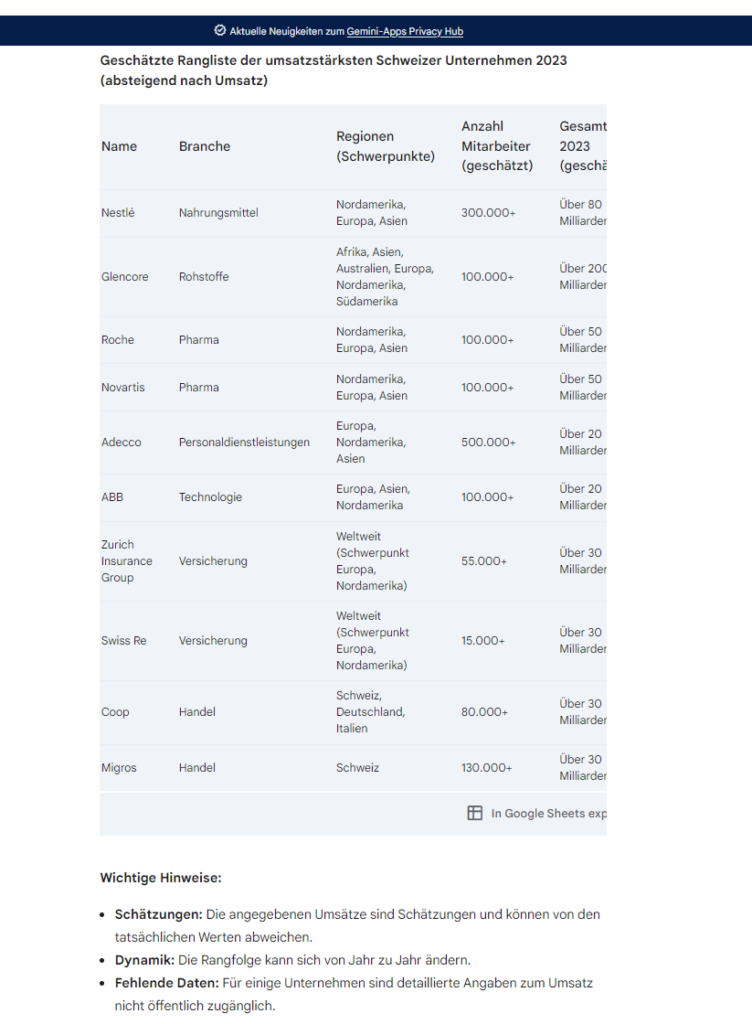
Nachdem ich die zusätzlichen Informationen von Gemini gelesen habe, frage ich mich, ob ich den Daten aus ChatGPT überhaupt vertrauen kann. Immerhin hat sich ChatGPT fast gar nicht abgegrenzt, keine relativen Quellen genannt und es war auch nicht offensichtlich, dass dieses LLM sich in Echtzeit an öffentlichen Quellen bedient hat.
Ich frage im Nachgang ChatGPT, wie er denn die Daten ermittelt hat
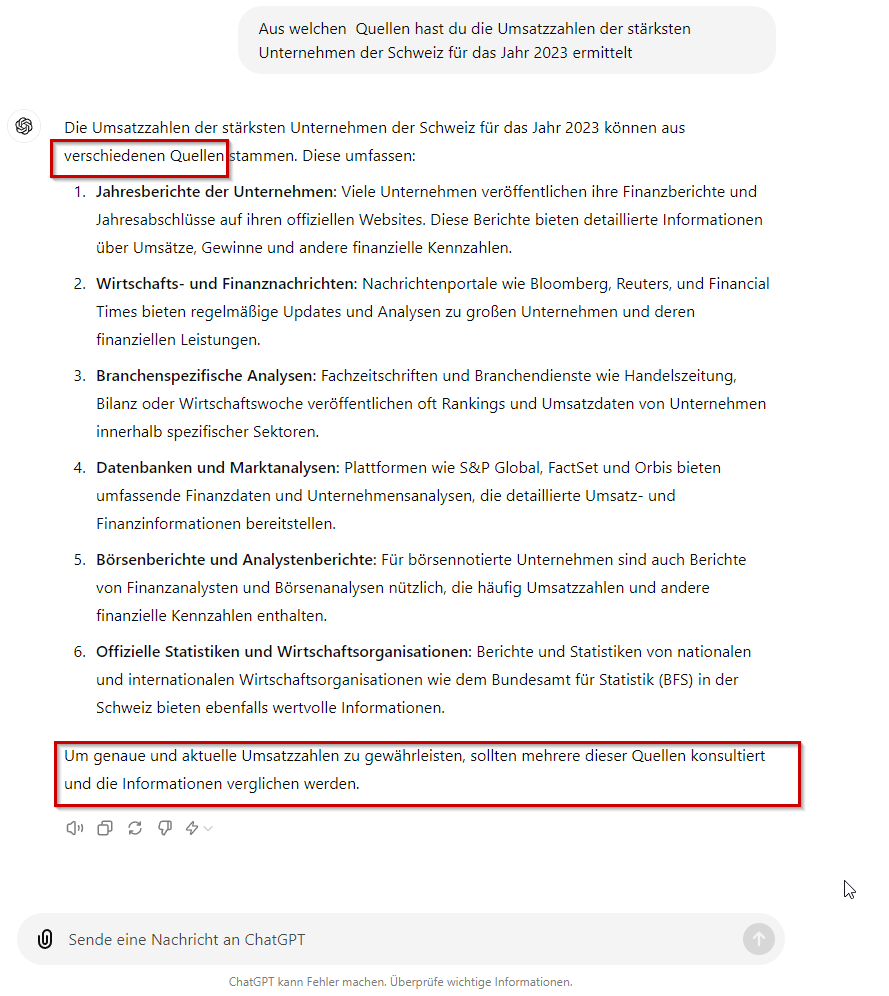
Bei ChatGPT ist es ebenfalls offensichtlich, dass die LLM sich bei der Antwort nicht an RAG Techniken simultan bedient. Es ist nicht klar, ob ChatGPT sein Output mit neuen Vektoren aus dem Embedded Modell anhand von Hintergrundrecherchen (z.B. im WWW) anreichert, oder sich am bereits trainierten Wissen bedient (naja, stochastisch versteht sich).
Hierzu teste ich jedoch das Ganze mit der File Upload Möglichkeit erneut. Zuvor möchte ich das ganze Ergebnis von GEMINI und ChatGPT mit den Ergebnissen der renommierten Institutionen wie STATISTA vergleichen. Ich gebe in der Suche von Statista einfach das Wort „Umsatzstärkste Unternehmen Schweiz in 2023“ ein. Leider hat die Statista zu 2023 keine solche Statistik veröffentlicht. Es gibt eine Statistik, welche die grössten Unternehmen wiedergibt. Diese sind jedoch nicht nach Umsatz bewertet, sondern nach dem Marktwert.

ChatGPT4o – Ein zweiter Versuch mit RAG und Stabilitätstest der Ergebnisse
Ich bilde einen zweiten, frischen Account auf OpenAI.com/chatgpt und kopiere die im ersten Account gestellt Frage als Prompt. Diesmal lade ich den öffentlich zugänglichen Geschäftsbericht von Glencore hoch, den ich unter der Adresse: https://www.glencore.com/.rest/api/v1/documents/static/d09d8212-4a9f-4034-b2d4-49152e5a0aff/GLEN-2023-Annual-Report.pdf
beziehen konnte und ergänze mein Prompt leicht, um die Datei, die ich zuvor hochgeladen hatte mit einbeziehen zu lassen. Das Ergebnis mündet nicht direkt in einer gewünschten Tabelle, doch ich kann mir sicher sein, dass ChatGPT diesmal RAG anwendet, um die Informationen in die aktuelle Session einzubinden:
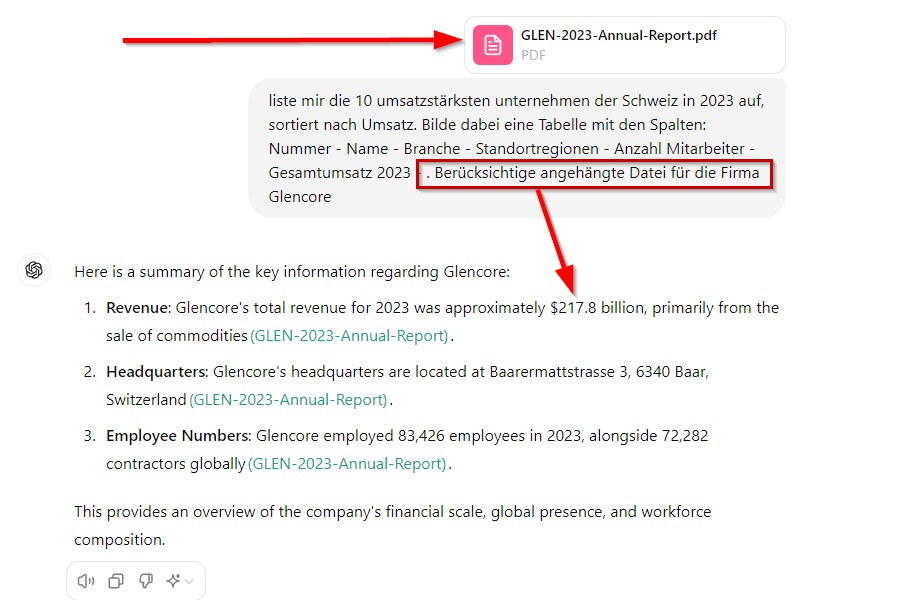
Ist diese Zahl wirklich aus dem Bericht von Glencore?
Ich will mir sicher gehen und suche nach diesen Zahlen im innerhalb der PDF Datei. Tatsächlich finde ich eine nicht ganz abgerundete Zahl, die der ermittelten Zahl von ChatGPT entspricht:
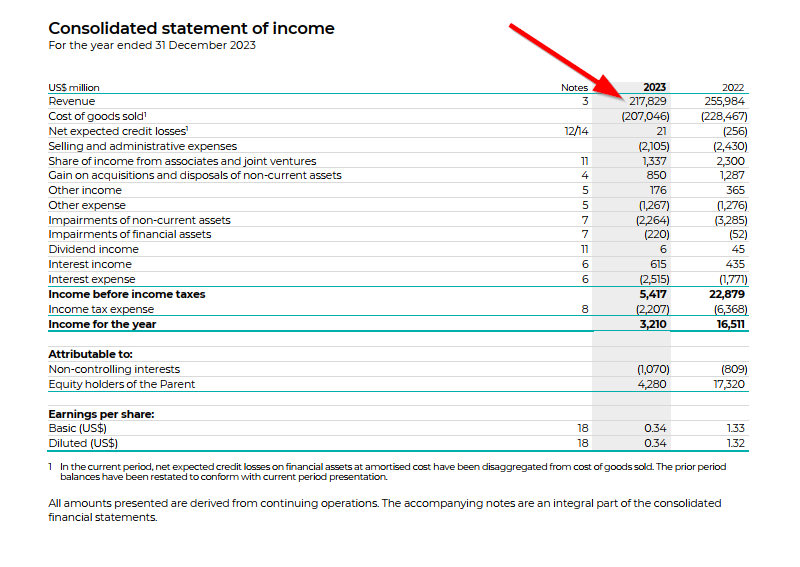
Ich möchte nun sicher gehen, dass ChatGPT nicht beim nächsten Prompt rückfällig wird und mir andere Zahlen in der Tabelle ausgibt, als die, die ich ihm als zusätzliches Wissen mitgegeben habe.

Auch der Vergleich der Anzahl Mitarbeiter ergibt einen Volltreffer im Geschäftsbericht. Erstaunlich ist es zudem, dass ChatGPT die Daten in einem Daten-Dschungel innerhalb der PDF Datei findet und sie semantisch bewerten kann.
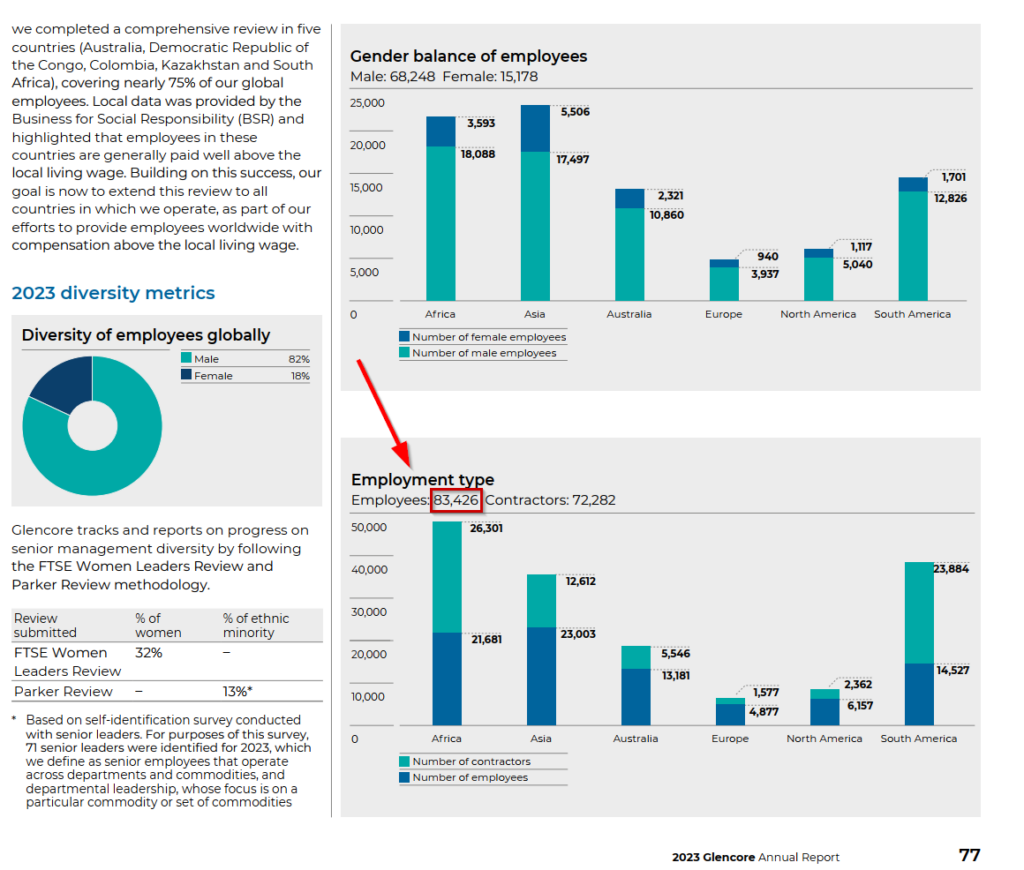
Das mag für sie vielleicht als einen relativ einfachen Vorgang erscheinen, doch die Ermittlung von Zahlen ist das Eine, diesen Zahlen im Kontext der Suche eine Bedeutung geben ist eine Andere.
Ich kann nun davon ausgehen, dass ChatGPT mit zugeführten Daten verlässliche Auswertungen nach Vorgaben machen kann, was meine Recherchen auf verlässliche Quellen aufbauend glaubwürdig erscheinen lässt. Von den übrigen Angaben innerhalb der Tabelle kann ich jedoch nicht das Gleiche behaupten. Die Zahlen der übrigen Unternehmen, deren Geschäftsberichte ChatGPT nicht mitgeteilt wurden, bleiben variabel, unverlässlich und entsprechend fragwürdig.
ChatGPT gibt glücklicher Weise selbst am Ende der Tabelle den kurzen Hinaus darauf, dass diese Daten nicht exakten Ermittlungen entsprechen, eine Nachrecherche somit notwendig wäre:
Diese Tabelle berücksichtigt Glencore als das umsatzstärkste Unternehmen, basierend auf den Informationen aus dem hochgeladenen Dokument. Andere Daten stammen aus öffentlich zugänglichen Quellen zu den jeweiligen Unternehmen.
FAZIT:
Wir haben den komplexen Prozess der Wissensbeschaffung beleuchtet und aufgezeigt, wie traditionelle Recherchemethoden und moderne KI-Technologien wie LLMs und RAG (Retrieval-Augmented Generation) diesen Prozess beeinflussen. Während der Mensch traditionell durch systematische Recherche, Analyse und Befragungen Wissen generiert, ermöglichen LLMs schnelle und bequeme Antworten, die jedoch oft mit Unsicherheiten verbunden sind.
Der Vergleich zwischen verschiedenen Systemen wie ChatGPT und Google Gemini verdeutlicht, dass trotz der Fortschritte bei der Textgenerierung, die Ergebnisse ohne kontextuell eingebettete Informationen variieren und unzuverlässig sein können.
RAG-gestützte Systeme bieten hierbei eine mögliche Verbesserung, indem sie Informationen aus externen Quellen einbinden. Dennoch bleibt eine kritische Prüfung der generierten Inhalte unerlässlich, um verlässliche Ergebnisse zu gewährleisten, insbesondere in Bezug auf komplexe und datenintensive Fragestellungen.
Übrigens werden insbesondere Lehrer und Lehrpersonal die RAG Technik noch aus einer ganz anderen Ecke her kennen, bzw. einen Querbezug darin entdeckt haben.
Die RAG-Technik (Relevantes ausarbeiten – Anreichern – Gestalten) ist eine didaktische Methode, die besonders in der Unterrichtsplanung und -gestaltung verwendet wird. Sie ist ein strukturiertes Verfahren, das es Lehrenden ermöglicht, Unterrichtsinhalte effektiv und zielgerichtet aufzubereiten.
1. Relevantes ausarbeiten:
In dieser Phase werden die zentralen Inhalte und Ziele des Themas identifiziert. Es geht darum, das Wesentliche herauszufiltern und die Lernziele klar zu definieren. Die Fokussierung auf das Wesentliche verhindert eine Überfrachtung des Unterrichts mit Informationen und ermöglicht eine klare Strukturierung.
2. Anreichern:
Das ausgewählte Wissen wird durch passende Materialien, Beispiele, Aufgaben und weiterführende Informationen ergänzt. Diese Phase dient dazu, den Lernprozess zu unterstützen und das Verständnis zu vertiefen. Dabei wird darauf geachtet, dass die Materialien dem Lernstand der Schüler*innen entsprechen und verschiedene Lernkanäle (visuell, auditiv, kinästhetisch) ansprechen.
3. Gestalten:
In dieser Phase geht es um die methodisch-didaktische Umsetzung im Unterricht. Hier wird entschieden, wie die Inhalte präsentiert werden, welche Methoden eingesetzt werden und wie die Schüler*innen aktiv einbezogen werden. Die Gestaltung sorgt für einen abwechslungsreichen, motivierenden und lerneffektiven Unterricht.







